Generating fake Hacker News headlines with Python
###TL;DR: All the code for this post is here.
One of my favorite hobbies is making up fake Hacker News headlines because they’re just so easy to parody (i.e. they follow a predictable pattern using most of the same topics and wording.)
- How to implement Rust in Go in a 3-line interpreter
- Ask HN: How do I serve better artisans beer at my startup?
- Javascript
- A [PDF] from some obscure industry journal from (1975)
- This outrageous thing is happening to our internet
- Isomorphic Javascript
- This outrageous thing is not happening to our internet
- Steve Jobs was a jerk
- Node.js
- Are you on Python 3 yet?
- Steve Jobs was a hero
- Steam still does not have managers and it is basically chaos over there
- How to run a Hadoop cluster using just Javascript for everything
- I hacked my own delivery drone together and now I’m on an FBI watch list
- Soylent: People eating people?
Markov chains, the ability to generate fake sentences and groups of text by computers based on real text previously generated by humans have the power to do this without me having to rack my brain.
The latest hotness in data science is to generate them with Python. They’ve become particularly prominent since the horse_ebooks account became ironically famous last year.
There have been a couple interesting Markov chain projects:
and, probably my personal absolute favorite, the Benedict Cumberbatch name generator. Ok, maybe this one’s not strictly a Markov chain project, but I’ll use any excuse I have to link to it.
There is something about fake Markov chain-generated Hacker News headlines that just hits the spot for me as a writer, data scientist, and tech news reader:
Understanding Markov Chains
Markov chains have been covered to death by people much smarter than me, but a quick explanation:
- There are two states in a Markov chain: what happens now, and what can happen next.
- Each state has a probability associated with it.
- What happens next depends only on what happened now, not what happened two or three steps ago, even if there are multiple “states.” I love this explanation and illustration, partly because guessing baby states of behavior are half of my life right now :):
If you made a Markov chain model of a baby’s behavior, you might include “playing,” “eating”, “sleeping,” and “crying” as states, which together with other behaviors could form a ‘state space’: a list of all possible states. In addition, on top of the state space, a Markov chain tells you the probability of hopping, or “transitioning,” from one state to any other state—e.g., the chance that a baby currently playing will fall asleep in the next five minutes without crying first.
Here’s a similar graphical example of a person’s morning routine that I also like a lot:
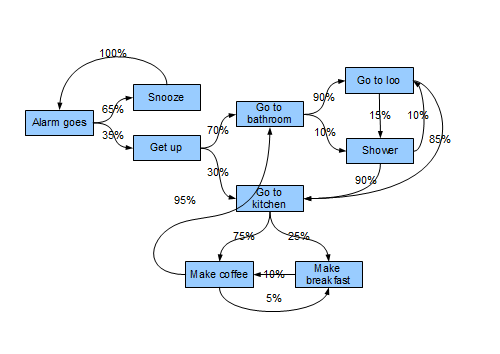
Not all of these things will happen every day (which is why some of the ebooks tweets are so nonsensical), but if you create a large enough sample, it should approximate real life.
How does this relate to news headlines?
Given a collection of sentences, how likely are you to have certain groups of words occur together before going to the next word? The more likely you are, aka, the more frequently certain tuples of words come up, the more “real” they are, and the more often the system will include them in the construction of new sentences. This frequency of changes is known as the probability of the transition of the state.
A great example of Markov chain-like functionality is text prediction in cell phones. The app will guess what your most likely next word is based on combinations of words you’ve typed in before (e.g. “morning” coming after “good”, or “how are you” based on, “hey.” HN headlines work the same way. There are a lot of words that repeat over and over again and the more likely the headline has already appeared, the more likely it is to appear again.
Based on the corpus I pulled below, some of the most common single words in HN titles (throwing out common ones like a, the, and):
veag:markovhn Vicki$ tr -c '[:alnum:]' '[\n*]' < headlines.txt | sort | uniq -c | sort -nr | head -50
Google, Ask, pdf, Amazon, programming, language
Not super-interesting because it’s only one sample of a huge set of headlines over history (this past Saturday) and single words as opposed to combinations. The Markov chain is this script on steroids, looking not only at single words, but at groups (i.e. “Google+ Amazon”) and how often those groups appear over all the possible groups.
##Technical requirements
- Get a copy of top x number of Hacker News headlines to use as a corpus.
- Keep a copy of all the scraped headlines.
- Pass that corpus into a Markov chain generator.
Getting HN Data
I started by trying to scrape Hacker News with Beautiful Soup. Let me preface this by saying that Beautiful Soup is a great library. But I always have such a PITA using it. Then I saw there was an unofficial HackerNews API. Unfortunately, it hasn’t been updated since January, which is forever in web data time. As I kept using it, I kept getting syntax errors having to deal with HN import errors, so I got a little frustrated.
Fortunately, HN has an official API which is up-to-date. So I used this code to pull in the top 500 headlines as of yesterday, and put them into a Python dictionary. The data needs to be in a dictionary structure in order to do things to tuples for the Markov chain generator:
import urllib2
import json
#HackerNews API documentation: https://github.com/HackerNews/API
api_url='https://hacker-news.firebaseio.com/v0/topstories.json'
item_url='https://hacker-news.firebaseio.com/v0/item/'
#Pull all story numbers into a Python data dictionary
response = urllib2.urlopen(api_url)
data=json.load(response)
#Takes each story number and extracts the title by treating as Python dictionary
with open("headlines.txt", "w") as output_file:
for i in data:
genurl="%s%s.json?print=pretty" % (item_url, i)
item_response=urllib2.urlopen(genurl)
parsed_response=json.load(item_response)
output_file.write(parsed_response["title"].encode('utf-8'))
Checking the content to make sure it pulled correctly (I checked against the front page. This is the closest snapshot to when I wrote it. )
veag:markovhn Vicki$ head -10 headlines.txt
Maintainer, sole developer, sole active user of the programming language SPITBOL
SQLite timeline items related to "json"
EasyOpenCL – The easiest way to get started with GPU programming
How to Fold a Julia Fractal
Feynman's Public Lectures on Quantum Electrodynamics
Post-quantum cryptography
Implementing a lightweight task scheduler in C++
Lisp for the Web, Part III
Hints on Programming Language Design (1973) [pdf]
Programming the Quantum Future
Generating the chains
There are tons of Python libraries for Markov chains. There is also a pretty good explanation here.
The two best sites, however, were this one, which had really nicely written code, and this one, which specifically dealt with scraping HN (although in a different way than I did it.)
I started with the Python adventures link, and got as far as the build_dict function when my imports started breaking. I had, stupidly, decided not to use Python 3 because I have Anaconda installed (for IPython notebooks) and all my Python instances aren’t virtualenv-ed yet, meaning it’s easier to just work with 2.7 for now until I get them all set up (Sorry, Guido.)
I decided to switch to the HN-specific Gist. Even though it was from 2013, which is ancient by web time standards, it didn’t have specifically to do with scraping code from shifting webpage structures, so it worked.
*Everything in the code is based on dictionaries and counting the number of groups in dictionaries. The structure for the rest of the program is is set up here, where the markov_map = defaultdict(lambda:defaultdict(int)) variable assignment at the beginning sets up a structure to create word-group dictionaries with counters, which then iterate through, counting the probabilities of each pair of words.
A couple of key points highlighted from the code (which is pretty well-commented as it stands).
- The code takes the headlines and splits them up into single words (like my Unix pipes did above), then groups each pair of words in a headline together to form a dictionary.
- The next bit of code calculates the probability of two words being together at the same time (the probability vectors mentioned above) based on the frequency that it happens in the actual corpus of text.
- The function starting with ```def sample(items):`` compares the probability of two words being together to the probability of the same phenomenon from a sampling distribution (the probability matrix).
- The final part,
sentences = []builds the sentences based onmarkov_map = defaultdict(lambda:defaultdict(int))created by splitting up the original headlines in the beginning and the probabilities of a word following two specific words in the sampling distribution. Titles that already at least partially exist, or are less than 100 words (as controlled by the probability matrix), are stripped out.
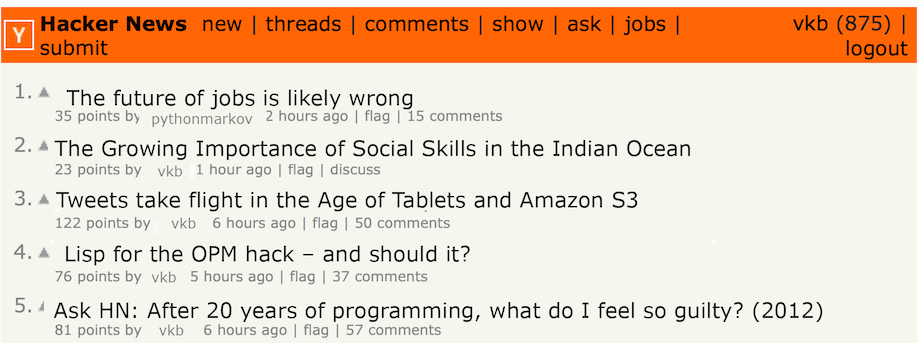
Headlines
Here are some my favorite headlines generated by the script based on what was on the front page on Saturday, August 22, 2015:
- How to convince your friends vertical farming is the next big language for the OPM hack – and should it?
- Tweets take flight in the Age of Tablets and Amazon S3
- 10 reasons you shouldn’t upgrade to Windows 10 updates
- Implementing a lightweight task scheduler in Rust
- The Future of Jobs Is Likely Wrong
- Ad Blockers and the Bees Were Not Enough: Aristotle’s Masterpiece
- Daniel Ek and Minecraft creator Notch debate Spotify privacy policy wants access to your photos
- The Growing Importance of Social Skills in the Google Search
Not sure who did better, Python or me. Points to me for silliness, points to Python for scary headlines verging on Clickhole levels of absurdity.